Parallel computing is necessary for venturing into the world of high performance computing. Parallel computing as the name suggests allows us to run a program parallelly. The preferred language of choice in our lab is Python and we can achieve parallel computation in python with the help of ‘mpi4py’ module. This comes with the standard installation of FEniCS, so if you have FEniCS installed on your system then you can directly work with MPI.
This post is based on my very limited understanding of the working of parallel programming, so if you find any error kindly let me know in the comments below. Now, some basics.
MPI stands for Message Passing Interface which is meant to be a tool to pass messages among various processes to carry out certain task. Processes corresponds to the physical cores available in your system. You can look for the number of cores available in your own computer by going into the task manager (On a windows computer) and looking for it in the Performance tab.
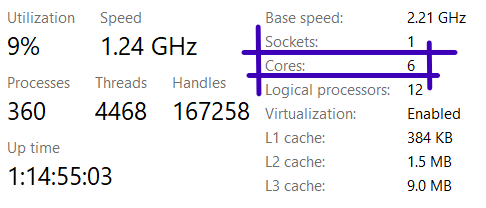
On my system, I have 6 physical cores. This means that I can parallelize my code to a maximum of 6 processes. Now the question is – how to achieve that with python?
Before that we need to understand a bit about MPI and its terminology.
MPI_COMM_WORLD: MPI uses objects called communicators, which are a collection of processes. The default communicator is called MPI_COMM_WORLD and it encompasses all the processes available. In my case the MPI_COMM_WORLD will look something like this:
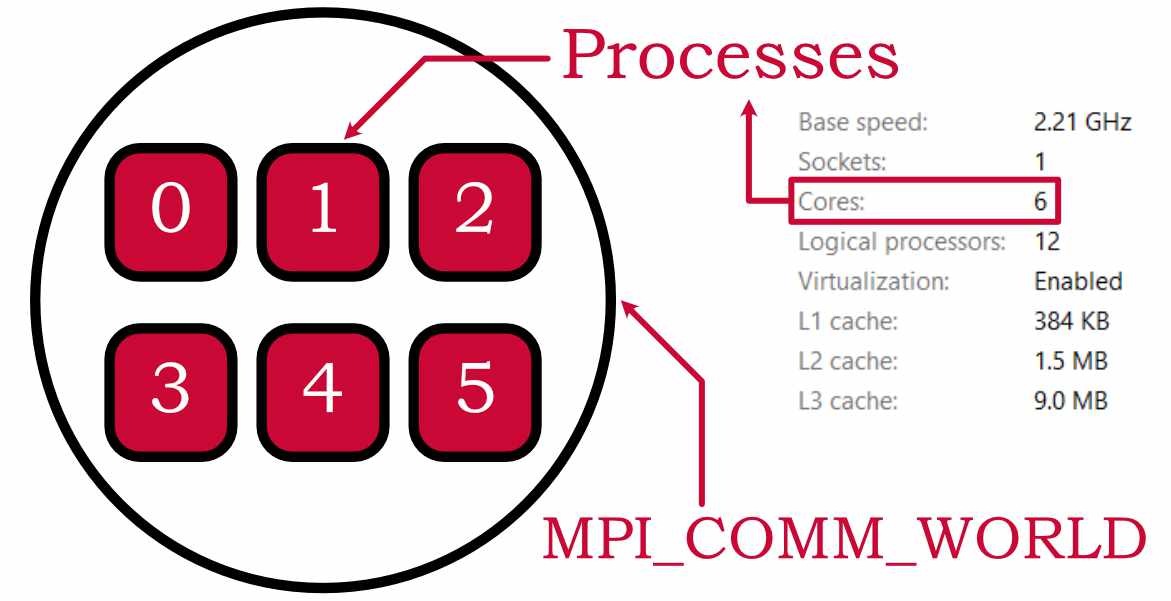
World Size: This would tell the program about the number of processors available in the world.
Processor Rank: This is a unique number assigned to each processor inside the world. The numbering starts from 0 as shown in the above figure.
Barrier: As the name suggests this acts as a barrier in the parallel execution. This forces MPI to execute all the commands before the barrier by all the processes. This is required in the situation where you need a certain variable generated by the program in all processes. This will become clear in the example presented below.
How do you run a script in parallel?
You can run any python script with MPI by typing the following command in terminal:
mpirun -np 6 python3 test-parallel.py
This will tell MPI to run test-parallel.py on 6 processors. The thing to understand here is that even though you are running the program on 6 processors, you are not actually doing parallel computations. You are just doing the same computation 6 times. To actually do parallel computations, you need to manually split the code to work parallelly. When you type the above command the system creates 6 different copies of the program file and sends it to 6 different processes.
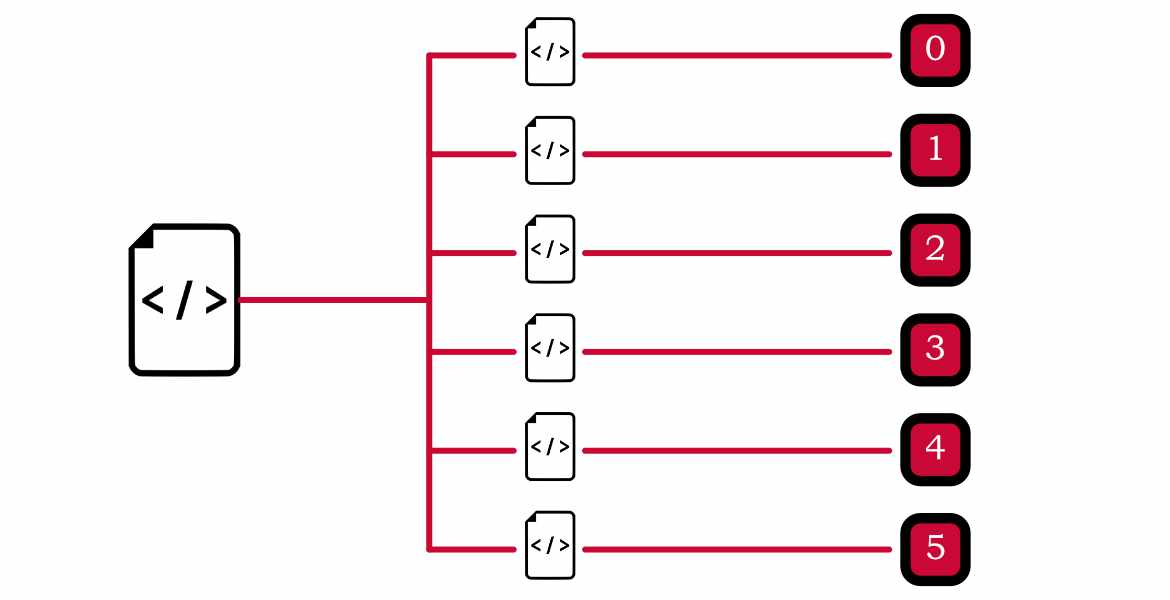
Thus we need to identify the processor number inside the program and execute the commands accordingly. We can identify the processor number by first getting a handle to the world communicator by using command
comm = MPI.COMM_WORLD
and then get the size of the world and the rank of the processor by using the commands
rank = comm.Get_rank()
size = comm.Get_size()
Based on this information we can modify our logic to run on multiple processors. This simple program sums the numbers from a to b and gives us the result. This logic is parallelizable. We can split the whole domain of calculation into the number of processors available and then add the numbers in that domain. Finally, we can add the results of all the processors. The program below is self-explanatory and you can run the same on your machine with the help of mpirun command.
import numpy
from mpi4py import MPI
import time
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
a = 1
b = 10000000
num_per_rank = b // size # the floor division // rounds the result down to the nearest whole number.
summ = numpy.zeros(1)
temp = 0
lower_bound = a + rank * num_per_rank
upper_bound = a + (rank + 1) * num_per_rank
print("This is processor ", rank, "and I am summing numbers from", lower_bound," to ", upper_bound - 1, flush=True)
comm.Barrier()
start_time = time.time()
for i in range(lower_bound, upper_bound):
temp = temp + i
summ[0] = temp
if rank == 0:
total = numpy.zeros(1)
else:
total = None
comm.Barrier()
# collect the partial results and add to the total sum
comm.Reduce(summ, total, op=MPI.SUM, root=0)
stop_time = time.time()
if rank == 0:
# add the rest numbers to 1 000 000
for i in range(a + (size) * num_per_rank, b + 1):
total[0] = total[0] + i
print("The sum of numbers from 1 to 1 000 000: ", int(total[0]))
print("time spent with ", size, " threads in milliseconds")
print("-----", int((time.time() - start_time) * 1000), "-----")
The only thing to notice is that the input to the loop changes according to the the processor number (rank). Thus instead of looping b times, each processor has to loop only num_per_rank times.
Running the above script on a single core result in the following output:
➜ pre-processing (master) time mpirun -np 1 python3 test-parallel.py
This is processor 0 and I am summing numbers from 1 to 60000000
The sum of numbers from 1 to 1 000 000: 1800000030000000
time spent with 1 threads in milliseconds
----- 5851 -----
real 0m6.824s
user 0m6.800s
sys 0m0.010s
and running the same code on 6 cores results in the following output
➜ pre-processing (master) time mpirun -np 6 python3 test-parallel.py
This is processor 0 and I am summing numbers from 1 to 10000000
This is processor 2 and I am summing numbers from 20000001 to 30000000
This is processor 3 and I am summing numbers from 30000001 to 40000000
This is processor 4 and I am summing numbers from 40000001 to 50000000
This is processor 1 and I am summing numbers from 10000001 to 20000000
This is processor 5 and I am summing numbers from 50000001 to 60000000
The sum of numbers from 1 to 1 000 000: 1800000030000000
time spent with 6 threads in milliseconds
----- 1668 -----
real 0m1.945s
user 0m11.250s
sys 0m0.200s
Thus we have achieved almost a 3.5\(\times\) boost in speed by running the code in parallel. Now, this was a trivial example but in real calculations, we can expect greater speed boosts. I hope you have understood the working of the command mpirun. If you have any doubts feel free to ask them in the comments.